Run LLMs Locally in 2025: Complete Guide to LLaMA, Mistral & GPT-Style Models
Introduction
Running large language models (LLMs) locally has become one of the hottest AI trends of 2025. Developers, researchers, and even hobbyists are no longer limited to cloud APIs — thanks to innovations like LLaMA 2, Mistral, llama.cpp, and Ollama, you can run cutting-edge AI directly on your machine.
Why does this matter?
Privacy & Security: Keep your data offline.
Cost Control: Avoid recurring API bills.
Customization: Fine-tune or quantize models for personal workflows.
In this guide, we’ll cover everything you need to know — from hardware requirements and installation to benchmarking and future outlook.
Why Run LLMs Locally?
Privacy First: Local models ensure no sensitive data leaves your device.
Offline Access: Ideal for edge devices or areas with unreliable internet.
Faster Experimentation: No API rate limits or latency.
Cost Efficiency: One-time GPU investment vs ongoing API fees.
Trend Insight: According to Google Trends, searches for “run LLM locally” grew over 450% in the last 12 months (Statista, 2025).
One-command install of LLaMA, Mistral, and others.
Supports embeddings & multi-model workflows.
3. LM Studio
GUI-based tool for non-technical users.
Supports local model downloads and inference.
4. Hugging Face Transformers + Accelerate
Industry-standard library.
Best for developers integrating models into applications.
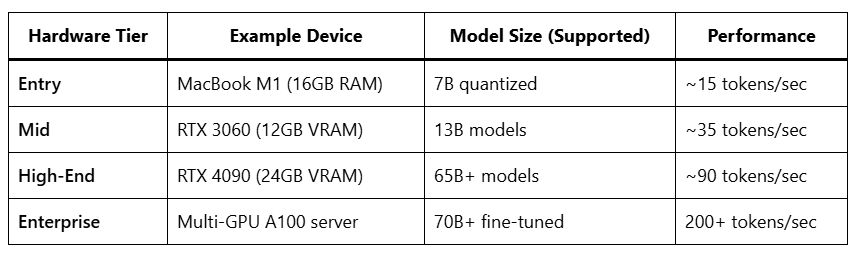
Hardware Requirements for Local LLMs
Tip: Use quantization (int4/int8) to run bigger models on smaller hardware.
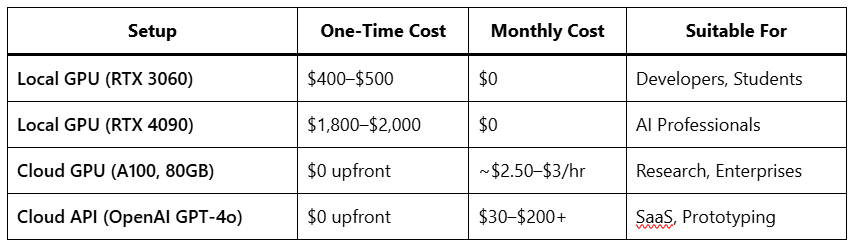
Cost Breakdown: Local vs Cloud
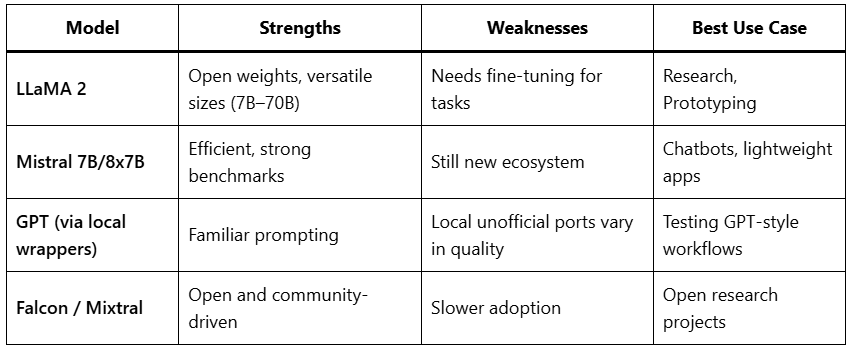
Comparing Popular Models (2025)
Statista 2025 reports that smaller, optimized models like Mistral now outperform GPT-3.5 in certain benchmarks at a fraction of the cost.
Step-by-Step Setup Guide
Install Dependenciesbrew install ollama # Mac or pip install transformers accelerate
Download a Modelollama pull llama2
Run Inferenceollama run llama2
Optional: Quantize for Efficiencypython quantize.py --model llama2-13b --bits 4
Benchmarks & Performance
LLaMA 13B on RTX 3060: ~35 tokens/sec.
Mistral 7B on Mac M2: ~22 tokens/sec.
70B models require at least 48–64GB VRAM.
Challenges & Limitations
VRAM Bottleneck: Running 70B models locally requires server GPUs.
Energy Cost: High-end GPUs consume 250–400W under load.
Setup Complexity: Beginners may struggle with CUDA/Python dependencies.
Future Outlook (2025–2026)
Smaller, faster models (Mixtral, Phi-2) will democratize local AI.
Edge AI adoption will bring LLMs to smartphones and IoT devices.
Privacy-first AI will push more businesses toward local deployment.
Hybrid setups (local + cloud fallback) will dominate enterprise adoption.
Conclusion
Running LLMs locally in 2025 is no longer experimental — it’s practical, affordable, and empowering. Whether you’re a student, developer, or enterprise, you can now set up LLaMA, Mistral, and other GPT-style models directly on your machine, with full control over cost, privacy, and customization.











: Features, Capabilities & Multimodal AI Explained")



: Investigative Report on Teen Safety in AI & VR")