Serverless ML Inference: Cost-Effective Options & Cloud Comparison
Table of Contents
Introduction
Are you wondering which cloud providers offer serverless containers with autoscaling for ML inference, or what are the most cost-effective serverless options for machine learning in the cloud? In 2025, serverless ML inference has become a popular solution for businesses and developers seeking scalable, cost-efficient deployment. This guide breaks down AWS, Google Cloud, and Azure serverless solutions, including GPU support, autoscaling, cold start mitigation, and LLM hosting, so you can make an informed decision.
Understanding Serverless ML Inference
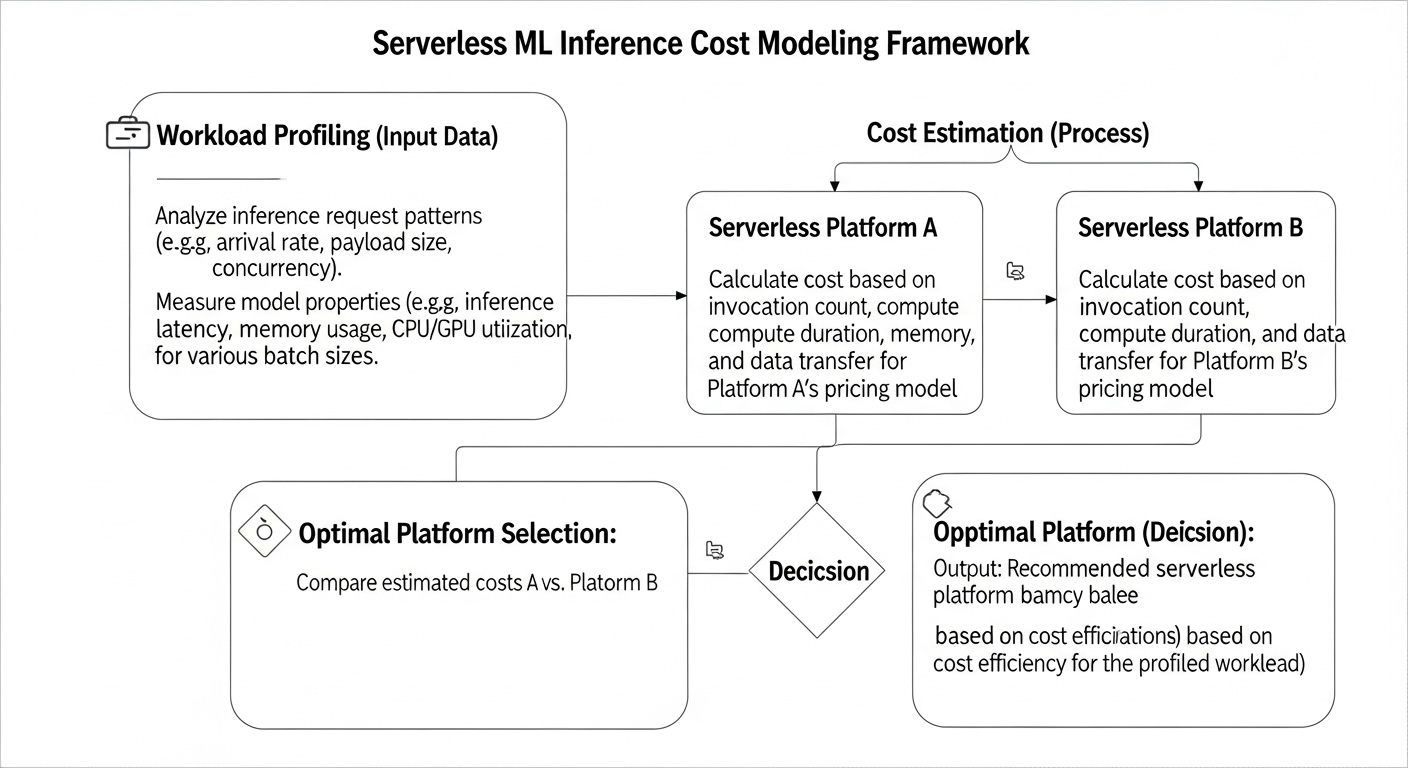
Serverless ML inference allows you to run machine learning models without managing servers. Resources automatically scale based on demand, and you pay only for actual compute usage. Serverless is ideal for:
Bursty or unpredictable workloads
Event-driven ML tasks
Small to medium CPU-based models
Rapid prototyping and proof-of-concept
Key benefits include operational simplicity, automatic scaling, and cost savings on idle resources.
Which Cloud Providers Offer Serverless Containers with Autoscaling for ML Inference?
Estimate Costs: Include compute, memory, invocations, and data transfer.
Include Operational Overhead: Server management, monitoring, scaling.
Compare Scenarios: Serverless vs dedicated; evaluate break-even points.
Start Small and Iterate: Begin with serverless, scale or migrate as usage grows.
Cold Start Considerations
Cold starts affect latency and cost, especially for large ML models or GPU inference:
Extra time for initializing functions and loading models
Mitigated with provisioned concurrency, container optimization, and pre-warming strategies
Crucial for latency-sensitive applications like real-time LLM inference
Serverless ML Inference FAQs
1. What is serverless inference? Serverless inference allows ML models to run in the cloud without managing servers. Autoscaling adjusts resources automatically, and you pay only for compute usage.
2. Which cloud providers offer serverless containers with autoscaling for ML inference?
AWS: SageMaker Serverless, Lambda + EKS Fargate
Google Cloud: Cloud Run, Vertex AI Predictions
Azure: Azure Functions, Azure Container Apps
3. What are the most cost-effective serverless options for ML inference?
CPU-based: AWS SageMaker Serverless, Google Cloud Run, Azure Container Apps
GPU-based: AWS Lambda with GPU, GCP Vertex AI with GPU scaling
4. How do serverless ML inference costs compare to dedicated containers?
Serverless: Cheaper for bursty, unpredictable workloads
Dedicated containers: Cheaper for steady, high-volume inference
5. How to reduce cold start times?
Use pre-warmed instances
Optimize container images and dependencies
Periodically ping functions
6. How to choose a serverless platform for LLM inference?
Serverless ML inference in 2025 offers scalable, operationally efficient, and cost-effective options for ML deployment. By carefully evaluating traffic patterns, model size, GPU needs, and cold start mitigation strategies, you can decide when serverless is the best choice and when dedicated containers or GPU clusters make more financial sense.
Using the frameworks, tables, and real-world scenarios in this guide, your ML deployment strategy can now be data-driven, cost-optimized, and fully aligned with your business needs.
[…] For instance, a simple classification or rephrasing task might go to a smaller, faster model like Gemini 2.5 Flash-Lite, while complex reasoning or creative generation is reserved for a more advanced model. This approach can lead to significant savings. If you’re managing various AI tools for personal productivity, you’ll appreciate the granular control this offers over costs. You can learn more about optimizing infrastructure costs in general by looking into strategies for serverless ML inference costs. […]














: Ultimate Guide to Boost Efficiency & Cut Costs")
")
[…] For instance, a simple classification or rephrasing task might go to a smaller, faster model like Gemini 2.5 Flash-Lite, while complex reasoning or creative generation is reserved for a more advanced model. This approach can lead to significant savings. If you’re managing various AI tools for personal productivity, you’ll appreciate the granular control this offers over costs. You can learn more about optimizing infrastructure costs in general by looking into strategies for serverless ML inference costs. […]