Table of Contents
How to Build AI Agents with LangChain in 2025: Complete Guide with Benchmarks & Best Practices
AI agents—intelligent systems capable of selecting tools, retrieving data, executing actions, and responding dynamically—are rapidly moving from research labs to real-world applications. LangChain agents have emerged as a leading framework for developers, offering reliable orchestration of language models, memory, tool integration, and workflow control.
In 2025, the industry focus has shifted from basic chatbots to advanced AI workflows that can reason, execute tasks, monitor results, and scale. Mastering the LangChain agents best practices 2025 is now critical for building production-ready systems. This step-by-step LangChain agents 2025 tutorial and guide covers everything: from agent architecture and cost optimization to the latest LangChain updates.
By the end of this guide, you’ll have a practical roadmap for creating intelligent agents—whether you’re building an email assistant, a research tool, or a full-scale workflow automation bot.
Step 1 — Define Your Agent’s Job & Use Case
- Scope concretely: Write 5-10 example tasks your agent should handle. E.g.: “schedule meeting”, “prioritize urgent emails”, “summarize document sections”, “answer customer FAQ from knowledge base”.
- Identify why LangChain is needed: If the task is simple (fixed logic, no external tool), a static script or rule-based function may suffice. Use agent architecture only when you need decisions, external data/tools, or chained reasoning. (LangChain blog “How to Build an Agent” emphasizes this. …)
- Pick evaluation metrics: accuracy, latency, cost per request, error rate, tool usage correctness. These benchmarks will guide architecture & testing.
Step 2 — Design Standard Operating Procedure & Workflow
- Design how a human would do the work. Create a Standard Operating Procedure (SOP):
- Break the task into sub-steps: classification, retrieval, tool calling, response generation, fallback/error handling.
- Identify what data sources / tools are needed: web search APIs, document databases, vector stores, calculators, file systems.
- Decide memory requirements: where will past context be stored? What needs long-term memory?
- Permissions & safety: what tool privileges does the agent have? How to restrict or sandbox tools? How to ensure responses don’t violate policy?
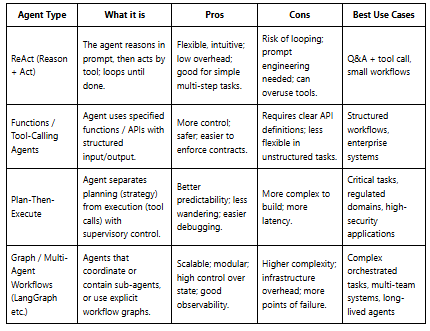
Step 3 — Choose Agent Architecture & Types
Different agent patterns suit different needs. Here’s a comparison:
Step 4 — Environment Setup & Core Tools
- Choose your LLM provider: OpenAI, Anthropic, local model (if needed). Adjust parameters: temperature, max tokens, etc.
- Set up Python environment: use Python 3.10/3.11, virtual env; version pinning for dependencies. (From expert guides: using
pyenv/condahelps.) - Install necessary packages:
pip install langchain openai python-dotenv pip install faiss-cpu # vector store if needed pip install {tool APIs} # e.g. SerpAPI, Wikipedia, custom APIs - Secure configuration: store secrets (API keys) in
.env, use IAM/policies for production tools. - Select memory store / vector database: e.g. Pinecone, Weaviate, or FAISS + disk persistence. Consider cost, speed, scale.
Step 5 — Build the MVP (Minimum Viable Agent)
- Focus on the SOP’s highest leverage task first (e.g. classification or intent detection).
- Write prompt(s) that cover the examples you prepared. Test these manually or via small dataset.
- Implement basic tool integration: one or two tools (e.g. web search + calculator or document retriever).
- Use an agent executor (LangChain) with verbose mode to see tool usage and agent decision steps. Debug mistakes early.
- Keep step count / tool usage limited to avoid runaway behavior or excessive cost.
Step 6 — Testing, Safety & Iteration
- Create test suite: feed your agent with the examples + edge cases. Do automated tests where possible.
- Monitor latency, correctness, fallback behaviour. Use telemetry / tracing tools (LangSmith, internal logging) to see how agent uses its tools.
- Safety / error handling: define fallback behavior (if a tool fails, if input unclear, etc).
- Prompt robustness: ensure prompt works reasonably even if input deviates (bad grammar, ambiguous, etc).
- Adjust memory & pruning logic: context windows may overflow; manage what past context is remembered / summarized.
Step 7 — Productionization, Deployment & Infrastructure
- Containerize or package as microservice: e.g. Docker + orchestrator (Kubernetes, serverless, etc).
- Scalability: concurrent requests; stateful agents if needed (session management); persistence of memory; autoscaling.
- Observability: logs, metrics (latency, error rate, tool usage), cost monitoring, alerting when misbehaviour or drift.
- Security & compliance: least privilege tool access; sandboxing; input sanitation; audit trails.
- Versioning: of prompts, agent configurations, tool definitions. Use tools like LangSmith or Git for version control.
- Failovers / fallback: if LLM provider fails, if tool API is down, option for human fallback.
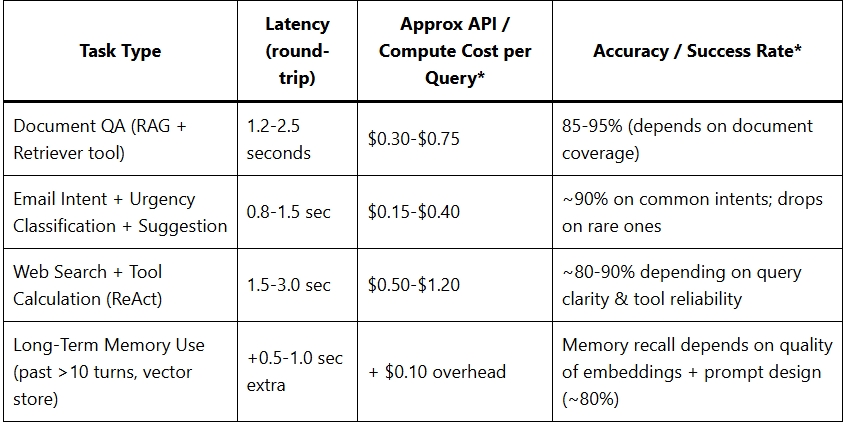
Data & Benchmark Table: Cost, Latency & Accuracy Benchmarks
Best Practices & Pitfalls to Avoid
- Too many tools early: increased cost, confusion, wrong tool usage. Start simple.
- Ambiguous prompt/tool descriptions: the agent picks wrong tool if descriptions are unclear. Always give good metadata (name, description) when defining tools.
- Ignoring memory constraints: context windows have limits; if you overpack history without summarizing, cost & latency degrade.
- Lack of monitoring or observability: you won’t know when agent misbehaves or costs balloon till too late.
- Security blind spots: tool calls may expose sensitive data; APIs may be misused; lacking oversight can cause serious issues.
Real-World Use Cases & Case Studies
- Email Scheduling / Personal Assistant Agents: e.g. “Email Agent” examples from LangChain blog. They handle parsing natural language requests, checking calendar availability, drafting replies. Case study: Cal.ai. …
- Customer Support / FAQ bots: Agents that connect to company knowledge bases, retrieve similar questions or documents, use tool or LLM to answer, sometimes refer to humans when uncertain.
- Automated Research Assistants: Aggregating information across sources; summarization; retrieving recent papers / news; combining tool + memory to retain context.
- Workflow Automation & Enterprise Systems: Agents that integrate with internal tools / APIs (CRM, databases), perform scheduled tasks (e.g. generate reports), or monitor logs / events and alert.
Future Outlook & Trends
- LangGraph & Graph-based agent runtimes are gaining traction for more durable, controllable, stateful agents. …
- Plan-Then-Execute & Hierarchical Control increasing in importance for safety & predictability.
- Better memory management and retrieval systems (hybrid: vector + symbolic) to deal with large context & past interactions.
- Cost optimization: quantization, selective tool usage, caching, reuse of retrieved info.
- Regulation, auditability, and explainability: As agents do more, companies will demand logs, explain-ability of agent decisions, compliance.
Conclusion & Actionable Tips
Building a LangChain agent in 2025 is both accessible and powerful—but success depends on starting with clarity, designing for safety & monitoring, and scaling thoughtfully. Here are action items:
- Define a tight scope and build your benchmark tasks.
- Choose an agent architecture that balances flexibility vs control.
- Build MVP, test heavily, monitor behavior.
- Prioritize memory design & cost control early.
- As you scale, invest in security, observability, infrastructure.
FAQs
What’s the difference between a LangChain agent and a simple LLM call?
A LangChain agent can decide which tools to use, perform external calls, remember past context (memory), orchestrate multi-step workflows. A basic LLM call is one shot: input → model → output, without tool usage or dynamic reasoning.
How many tools is too many?
Start small — using 1-2 tools initially. Each tool adds complexity including latency, cost, debugging. Expand only once core functionality is stable.
How to manage cost for agents using expensive LLMs + tools?
Strategies include switching models for less critical tasks, caching results, pruning memory, limiting token usage, controlling tool usage, and choosing providers or local models wisely.
Can I use LangChain without coding?
Custom agents usually require code for tool integrations, memory design, and orchestrators. Some no-code platforms wrap around such frameworks, but flexibility is limited without coding.
What are common failure modes and how to mitigate?
Common failure modes include tool misuse, prompt drift, memory overload, high latency, cost blow-ups. Mitigation involves clear tool descriptions, strong prompt engineering, test suites, monitoring, and safe error handling.